--------------------[整理]鲲鹏性能优化十板斧系列文章--------------------
| 鲲鹏性能优化十板斧(一)——鲲鹏处理器NUMA简介与性能调优五步法<TaiShan特战队出品>
| 鲲鹏性能优化十板斧(二)——CPU与内存子系统性能调优<TaiShan特战队出品>
| 鲲鹏性能优化十板斧(三)——网络子系统性能调优<TaiShan特战队出品>
| 鲲鹏性能优化十板斧(四)——磁盘IO子系统性能调优<TaiShan特战队出品>
| 鲲鹏性能优化十板斧(五)——应用程序性能调优<TaiShan特战队出品>
---------------------------------------------------------------------------------------------------
NUMA 架构下的软件性能挑战
CPU 从单核到 SMP。由于功耗墙的存在,单核的性能发展遇到了瓶颈。从 2006 年左右开始,所有的 PC、服务器的处理器,都迈入了多核时代。这时出现了多核架构,称为 SMP:对称多处理系统。在 SMP 架构下的计算机中,每个核都是对等的,所有的核通过总线访问所有内存,每个进程在调度时,可以在任意一个核上运行,在操作系统和内核的支持下,整个系统能做到非常好的负载均衡,性能得到很好的发挥。
从 SMP 到 NUMA。所有的核均通过总线访问内存,当核数不断增加的时候,内存总线成为了瓶颈。为了解决这一问题,NUMA 架构出现了,非统一的内存访问架构。在 NUMA 架构下,CPU 被分成了多个节点 Node。每个节点有自己的内存 Controller,不再受内存总线带宽的限制。每个 NUMA 节点上面有自己的内存控制器、有自己的内存。这里面带来两个概念,第一个概念 CPU 有了节点,第二,虽然所有内存在整个服务器上都是可见的,实际上在物理上内存是分布式的,他们通过不同的结点、通过不同的内存访问器去访问的,就有了距离。
围绕NUMA的性能优化,核心的目标就是访问最短距离的内存。当核数越来越多之后,软件的并发能力就会有新挑战。视频的后半段分析了锁的时间模型,以及性能优化的一些建议。
1.1 鲲鹏处理器NUMA简介
随着现代社会信息化、智能化的飞速发展,越来越多的设备接入互联网、物联网、车联网,从而催生了庞大的计算需求。但是功耗墙问题以功耗和冷却两大限制极大的影响了单核算力的发展。为了满足智能世界快速增长的算力需求,多核架构成为最重要的演进方向。
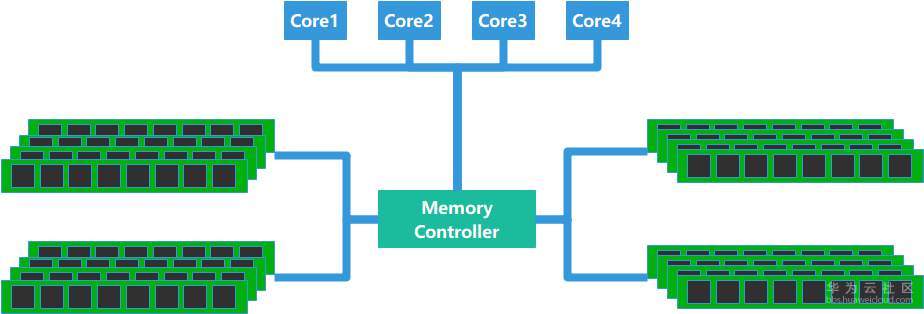
传统的多核方案采用的是SMP(Symmetric Multi-Processing)技术,即对称多处理器结构,如图1-1所示。在对称多处理器架构下,每个处理器的地位都是平等的,对内存的使用权限也相同。任何一个程序或进程、线程都可以分配到任何一个处理器上运行,在操作系统的支持下,可以达到非常好的负载均衡,让整个系统的性能、吞吐量有较大提升。但是,由于多个核使用相同的总线访问内存,随着核数的增长,总线将成为瓶颈,制约系统的扩展性和性能。
图1-1 对称多处理器SMP架构
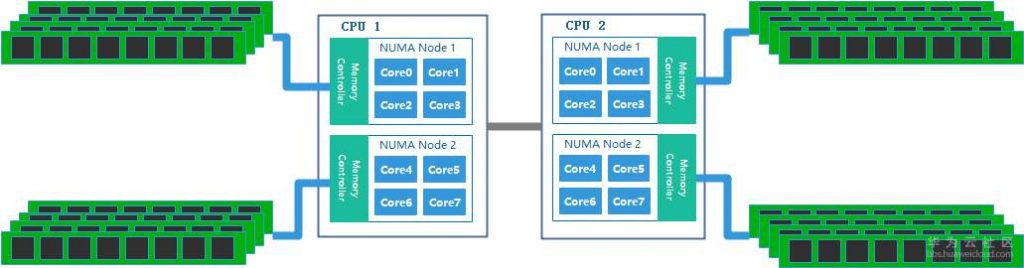
鲲鹏处理器支持NUMA(Non-uniform memory access, 非统一内存访问)架构,能够很好的解决SMP技术对CPU核数的制约。NUMA架构将多个核结成一个节点(Node),每一个节点相当于是一个对称多处理机(SMP),一块CPU的节点之间通过On-chip Network通讯,不同的CPU之间采用Hydra Interface实现高带宽低时延的片间通讯,如图1-2所示。在NUMA架构下,整个内存空间在物理上是分布式的,所有这些内存的集合就是整个系统的全局内存。每个核访问内存的时间取决于内存相对于处理器的位置,访问本地内存(本节点内)会更快一些。Linux内核从2.5版本开始支持NUMA架构,现在的操作系统也提供了丰富的工具和接口,帮助我们完成就近访问内存的优化和配置。所以,使用鲲鹏处理器所实现的计算机系统,通过适当的性能调优,既能够达成很好的性能,又能够解决SMP架构下的总线瓶颈问题,提供更强的多核扩展能力,以及更好更灵活的计算能力。
图1-2 NUMA架构
1.2 性能调优五步法
性能优化通常可以通过如表1-1五个步骤完成。
表1-1 性能优化的通用步骤
| 序号 | 步骤 | 说明 |
| 1 | 建立基准 | 在进行优化或者开始进行监视之前,首先要建立一个基准数据和优化目标。这个基准包括硬件配置、组网、测试模型、系统运行数据(CPU/内存/IO/网络吞吐/响应延时等)。我们需要对系统做全面的评估和监控,才能更好的分析系统性能瓶颈,以及实施优化措施后系统的性能变化。优化目标即是基于当前的软硬件架构所期望系统达成的性能目标。性能调优是一个长期的过程,在优化工作的初期,很容易识别瓶颈并实施有效的优化措施,优化成果往往也很显著,但是越到后期优化的难度就越大,优化措施更难寻找,效果也将越来越弱。因此我们建议有一个合理的平衡点。 |
| 2 | 压力测试与监视瓶颈 | 使用峰值工作负载或专业的压力测试工具,对系统进行压力测试。使用一些性能监视工具观察系统状态。在压力测试期间,建议详细记录系统和程序的运行状态,精确的历史记录将更有助于分析瓶颈和确认优化措施是否有效。 |
| 3 | 确定瓶颈 | 压力测试和监视系统的目的是为了确定瓶颈。系统的瓶颈通常会在CPU过于繁忙、IO等待、网络等待等方面出现。需要注意的是,识别瓶颈是分析整个测试系统,包括测试工具、测试工具与被测系统之间的组网、网络带宽等。有很多“性能危机”的项目其实是由于测试工具、测试组网等这些很容易被忽视的环节所导致的,在性能优化时应该首先花一点时间排查这些环节。 |
| 4 | 实施优化 | 确定了瓶颈之后,接着应该对其进行优化。本文总结了笔者所在团队在项目中所遇到的常见系统瓶颈和优化措施。我们需要注意的是,系统调优的过程是在曲折中前进,并不是所有的优化措施都会起到正面效果,负优化也是经常遇到的。所以我们在准备好优化措施的同时,也应该准备好将优化措施回滚的操作指导。避免因为实施了一些不可逆的优化措施导致重新恢复环境而浪费大量的时间和精力。 |
| 5 | 确认优化效果 | 实施优化措施后,重新启动压力测试,准备好相关的工具监视系统,确认优化效果。产生负优化效果的措施要及时回滚,调整优化方案。如果有正优化效果,但未达到优化目标,则重复步骤2“压力测试与监视瓶颈”,如达成优化目标,则需要将所有有效的优化措施和参数总结、归档,进入后续生产系统的版本发布准备等工作中。 |
在性能调优经验比较少或者对系统的软硬件并不是非常了解时,可以参考使用五步法的模式逐步展开性能调优的工作。对于有丰富调优经验的工程师,或者对系统的性能瓶颈已经有深入洞察的专家,也可以采用其他方法或过程展开优化工作。
=====结束分隔符=====
上述文章转载自华为云社区:
【1024程序员节献礼】鲲鹏性能优化十板斧——鲲鹏处理器NUMA简介与性能调优五步法<TaiShan特战队出品>
转载仅供学习,如有侵权,请第一时间告知,本站第一时间删除。
站长邮箱:MzQ1MTYxOTc0QHFxLmNvbQ==
文章的脚注信息由WordPress的wp-posturl插件自动生成

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~![[整理]鲲鹏性能优化十板斧(五)——应用程序性能调优<TaiShan特战队出品>](http://www.jyguagua.com/wp-content/themes/begin/timthumb.php?src=http://www.jyguagua.com/wp-content/uploads/2020/03/1-4.jpg&w=280&h=210&zc=1)
![[整理]鲲鹏性能优化十板斧(四)——磁盘IO子系统性能调优<TaiShan特战队出品>](http://www.jyguagua.com/wp-content/themes/begin/timthumb.php?src=https://bbs-img.huaweicloud.com/blogs/img/1572357064241058.png&w=280&h=210&zc=1)
![[整理]鲲鹏性能优化十板斧(三)——网络子系统性能调优<TaiShan特战队出品>](http://www.jyguagua.com/wp-content/themes/begin/timthumb.php?src=https://bbs-img.huaweicloud.com/blogs/img/1572166310484634.png&w=280&h=210&zc=1)
![[整理]鲲鹏性能优化十板斧(二)——CPU与内存子系统性能调优<TaiShan特战队出品>](http://www.jyguagua.com/wp-content/themes/begin/timthumb.php?src=http://www.jyguagua.com/wp-content/uploads/2020/03/1.jpg&w=280&h=210&zc=1)