--------------------[整理]鲲鹏性能优化十板斧系列文章--------------------
| 鲲鹏性能优化十板斧(一)——鲲鹏处理器NUMA简介与性能调优五步法<TaiShan特战队出品>
| 鲲鹏性能优化十板斧(二)——CPU与内存子系统性能调优<TaiShan特战队出品>
| 鲲鹏性能优化十板斧(三)——网络子系统性能调优<TaiShan特战队出品>
| 鲲鹏性能优化十板斧(四)——磁盘IO子系统性能调优<TaiShan特战队出品>
| 鲲鹏性能优化十板斧(五)——应用程序性能调优<TaiShan特战队出品>
---------------------------------------------------------------------------------------------------
1 应用程序调优
1.1 调优简介
应用程序部署到鲲鹏服务器上以后,需要结合芯片和服务器的特点优化代码性能,使硬件能力得到充分发挥。本章列举几个典型场景,涉及锁、编译器配置、Cacheline、缓冲机制等优化。
1.2 优化方法
1.2.1 优化编译选项,提升程序性能
原理
C/C++代码在编译时,gcc编译器将源码翻译成CPU可识别的指令序列,写入可执行程序的二进制文件中。CPU在执行指令时,通常采用流水线的方式并行执行指令,以提高性能,因此指令执行顺序的编排将对流水线执行效率有很大影响。通常在指令流水线中要考虑:执行指令计算的硬件资源数量、不同指令的执行周期、指令间的数据依赖等等因素。我们可以通过通知编译器,程序所运行的目标平台(CPU)指令集、流水线,来获取更好的指令序列编排。在gcc 9.1.0版本,支持了鲲鹏处理器所兼容的armv8指令集、tsv110流水线。
修改方式
l 在Euler系统中使用HCC编译器,可以在CFLAGS和CPPFLAGS里面增加编译选项:
-mtune=tsv110 -march=armv8-a
l 在其它操作系统中,可以升级GCC版本到9.10,并在CFLAGS和CPPFLAGS里面增加编译选项:
-mtune=tsv110 -march=armv8-a
1.2.2 文件缓冲机制选择
原理
内存访问速度要高于磁盘,应用程序在读写磁盘时,通常会经过一些缓存,以减少对磁盘的直接访问,如下图所示:

clib buffer:clib buffer是用户态的一种数据缓冲机制,在启用clib buffer的情况下,数据从应用程序的buffer拷贝至clib buffer后,并不会立即将数据同步到内核,而是缓冲到一定规模或者主动触发的情况下,才会同步到内核;当查询数据时,会优先从clib buffer查询数据。这个机制能减少用户态和内核态的切换(用户态切换内核态占用一定资源)。
PageCache:PageCache是内核态的一种文件缓存机制,用户在读写文件时,先操作PageCache,内核根据调度机制或者被应用程序主动触发时,会将数据同步到磁盘。PageCache机制能减少磁盘访问。
修改方式
应用程序根据自己的业务特点选择合适的文件读写方式:
l fread/fwrite函数使用了clib buffer缓存机制,而read/write并没有使用,因此fread/fwrite比read/write多一层内存拷贝,即从应用程序buffer至clib buffer的拷贝,但是fread/fwrite比read/write有更少的系统调用。因此对于每次读写字节数较大的操作,内存拷贝比系统调用占用更多资源,可以使用read/write来减少内存拷贝;对于每次读写字节数较少的操作,系统调用比内存拷贝占用更多资源,建议使用fread/ fwrite来减少系统调用次数。
l O_DIRECT模式没有使用PageCache,因此少了一层内存拷贝,但是因为没有缓冲导致每次都是从磁盘里面读取数据。
O_DIRECT主要适用场景为:应用程序有自己的缓冲机制;数据读写一次后,后面不再从磁盘读这个数据。
1.2.3 执行结果缓存
原理
对于相同的输入,应用软件经过计算后,有相同的输出,可以将运算结果保存,在下次有相同的输入时,返回上次执行的结果。
修改方式
目前部分开源软件已经实现这种机制,举例如下:
1. Nginx缓冲
基于局部性原理,Nginx使用proxy_cache_path等参数将请求过的内容在本地内存建立一个副本,这样对于缓存中的文件不用去后端服务器去取。
2. JIT编译
JIT(Just-In-Time)编译,将输入文件转为机器码。为了提升效率,转换后的机器码被缓存在内存,这样相同的输入(如JAVA程序的字节码)不用重新翻译,直接返回缓存中的内容。如果发现JAVA虚拟机的C1 Compiler/C2 Compiler线程的CPU占用比较多,可能是JIT缓冲不够,可以增加JAVA虚拟机ReservedCodeCacheSize参数。
1.2.4 减少内存拷贝
原理
基于数据流分析,发现并减少内存拷贝次数,能降低CPU使用率,并减少内存带宽占用。
修改方式
减少内存拷贝要基于业务逻辑进行分析,这里例举几种减少内存拷贝的实现机制:
l 样例一:使用sendfile代替send/sendto/write等函数将文件发送给对端
如下两条语句将文件发送给对端,一般会有4次内存拷贝
ssize_t read (int fd, void *buf, size_t count);
ssize_t send (int s, const void * buf, size_t len, int flags);
− read函数一般有2次内存拷贝: DMA将数据搬运到内核的PageCache;内核将数据搬运到应用态的buf。
− send函数一般有2次内存拷贝: write函数将应用态的buf的拷贝到内核;DMA将数据搬运到网卡。
使用如下函数实现只需要两次内存拷贝:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
内核通过 DMA将文件搬运到缓存(一次内存拷贝),然后把缓存的描述信息(位置和长度)传递给TCP/IP协议栈,内核在通过DMA将缓冲搬运到网卡(第二次内存拷贝)。
除了修改代码,部分开源软件已经支持这个特性,如Nginx可以通过sendfile on参数打开这个功能。
l 样例二:进程间通信使用共享内存代替socket/pipe通信
内存共享方式可以让多个进程操作同样的内存区域,相比socket通信的的方式,内存拷贝少。应用程序可以使用shmget等函数实现进程间通信。
1.2.5 锁优化
原理
自旋锁和CAS指令都是基于原子操作指令实现,当应用程序在执行原子操作失败后,并不会释放CPU资源,而是一直循环运行直到原子操作执行成功为止,导致CPU资源浪费。如下图代码的黄色部分是一个循环等待过程:
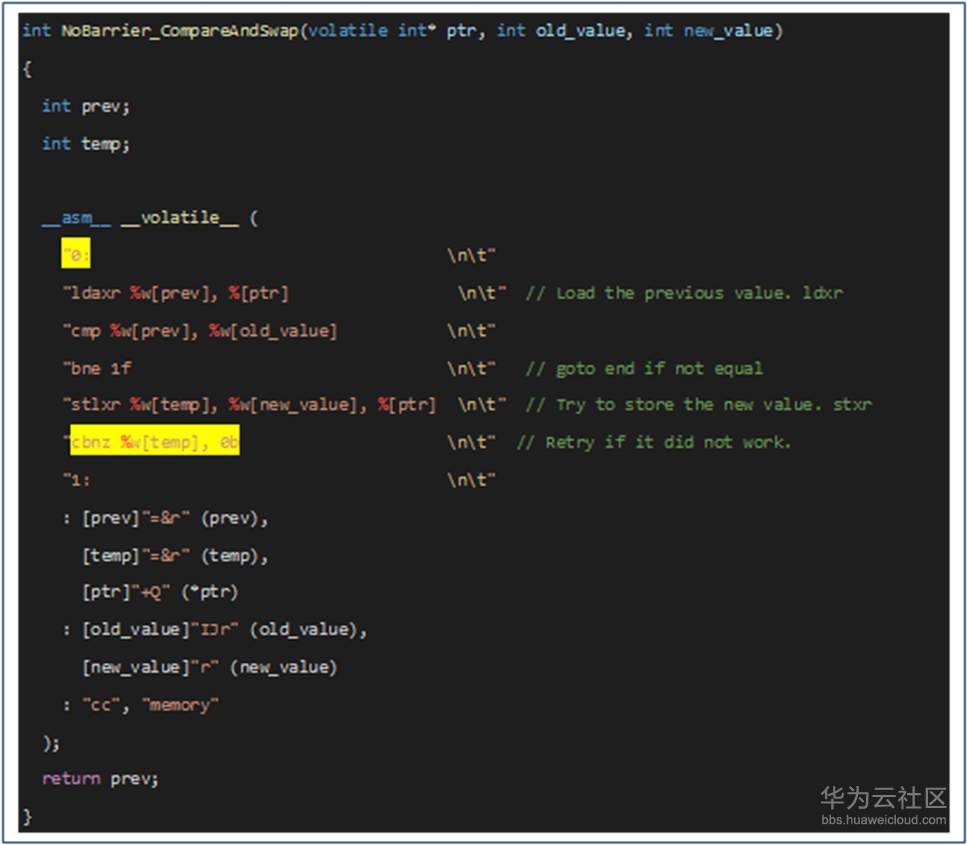
修改方式
可以通过perf top分析占用CPU资源靠前的函数,如果锁的申请和释放在5%以上,可以考虑优化锁的实现,修改思路如下:
1. 大锁变小锁:并发任务高的场景下,如果系统中存在唯一的全局变量,那么每个CPU core都会申请这个全局变量对应的锁,导致这个锁的争抢严重。可以基于业务逻辑,为每个CPU core或者线程分配对应的资源。
2. 使用ldaxr+stlxr两条指令实现原子操作时,可以同时保证内存一致性,而ldxr+stxr指令并不能保存内存一致性,从而需要内存屏障指令(dmb ish)配合来实现内存一致性。从测试情况看,ldaxr+stlxr指令比ldxr+stxr+dmb ish指令的性能高。
3. 减少线程并发数:参考2.3.5 调整线程并发数章节。
4. 对锁变量使用Cacheline对齐:对于高频访问的锁变量,实际是对锁变量进行高频的读写操作,容易发生伪共享问题。具体优化可以参考5.2.7 Cacheline 优化章节。
5. 优化代码中原子操作的实现。下图代码为某软件的代码实现:
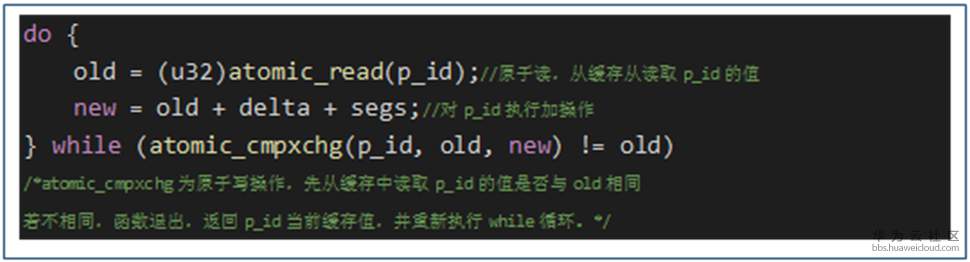
从函数调用逻辑上看,在while循环会重复执行原子读、变量加以及原子写入操作,代码语句多。优化思路:使用atomic_add_return指令替换这个代码流程,简化指令,提高性能。替换后的代码如下图:

1.2.6 使用jemalloc优化内存分配
原理
jemalloc是一款内存分配器,与其它内存分配器(glibc)相比,其最大优势在于多线程场景下内存分配性能高以及内存碎片减少。充分发挥鲲鹏芯片多核多并发优势,推荐业务应用代码使用jemalloc进行内存分配。
在内存分配过程中,锁会造成线程等待,对性能影响巨大。jemalloc采用如下措施避免线程竞争锁的发生:使用线程变量,每个线程有自己的内存管理器,分配在这个线程内完成,就不需要和其它线程竞争锁。
修改方式
步骤 1 下载jemalloc,参考INSTALL.md编译安装。
源码下载地址https://github.com/jemalloc/jemalloc
步骤 2 修改应用软件的链接库的方式,在编译选项中添加如下编译选项:
-I`jemalloc-config --includedir`-L`jemalloc-config --libdir` -Wl,-rpath,`jemalloc-config --libdir` -ljemalloc `jemalloc-config --libs`
具体参考 https://github.com/jemalloc/jemalloc/wiki/Getting-Started
步骤 3 部分开源软件可以修改配置参数来指定内存分配库,如MySql可以配置my.cnf文件:malloc-lib=/usr/local/lib/libjemalloc.so
----结束
1.2.7 Cacheline 优化
原理
CPU标识Cache中的数据是否为有效数据不是以内存位宽为单位,而是以Cacheline为单位。这个机制可能会导致伪共享(false sharing)现象,从而使得CPU的Cache命中率变低。出现伪共享的常见原因是高频访问的数据未按照Cacheline大小对齐:
Cache空间大小划分成不同的Cacheline,示意图如下,readHighFreq虽然没有被改写,且在Cache中,在发生伪共享时,也是从内存中读:

例如以下代码定义两个变量,会在同一个Cacheline中,Cache会同时读入:
int readHighFreq, writeHighFreq
其中readHighFreq是读频率高的变量,writeHighFreq为写频率高的变量。writeHighFreq在一个CPU core里面被改写后,这个cache 中对应的Cacheline长度的数据被标识为无效,也就是readHighFreq被CPU core标识为无效数据,虽然readHighFreq并没有被修改,但是CPU在访问readHighFreq时,依然会从内存重新导入,出现伪共享导致性能降低。
鲲鹏920和x86的Cacheline大小不一致,可能会出现在X86上优化好的程序在鲲鹏 920上运行时的性能偏低的情况,需要重新修改业务代码数据内存对齐大小。X86 L3 cache的Cacheline大小为64字节,鲲鹏920的Cacheline为128字节。
修改方式
1. 修改业务代码,使得读写频繁的数据以Cacheline大小对齐,修改方法可参考:
a. 使用动态申请内存的对齐方法:
int posix_memalign(void **memptr, size_t alignment, size_t size)
调用posix_memalign函数成功时会返回size字节的动态内存,并且这块内存的起始地址是alignment的倍数。
b. 局部变量可以采用填充的方式:
int writeHighFreq;
char pad[CACHE_LINE_SIZE - sizeof(int)];
代码中CACHE_LINE_SIZE是服务器Cacheline的大小,pad变量没有用处,用于填充writeHighFreq变量余下的空间,两者之和是CacheLine大小。
2. 部分开源软件代码中有Cacheline的宏定义,修改宏的值即可。如在impala使用CACHE_LINE_SIZE宏来表示目标平台的Cacheline大小。
=====结束分隔符=====
上述文章转载自华为云社区:
【1024程序员节献礼】鲲鹏性能优化十板斧(五)——应用程序性能调优<TaiShan特战队出品>
转载仅供学习,如有侵权,请第一时间告知,本站第一时间删除。
站长邮箱:MzQ1MTYxOTc0QHFxLmNvbQ==
文章的脚注信息由WordPress的wp-posturl插件自动生成

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~![[整理]鲲鹏性能优化十板斧(四)——磁盘IO子系统性能调优<TaiShan特战队出品>](http://www.jyguagua.com/wp-content/themes/begin/timthumb.php?src=https://bbs-img.huaweicloud.com/blogs/img/1572357064241058.png&w=280&h=210&zc=1)
![[整理]鲲鹏性能优化十板斧(三)——网络子系统性能调优<TaiShan特战队出品>](http://www.jyguagua.com/wp-content/themes/begin/timthumb.php?src=https://bbs-img.huaweicloud.com/blogs/img/1572166310484634.png&w=280&h=210&zc=1)
![[整理]鲲鹏性能优化十板斧(二)——CPU与内存子系统性能调优<TaiShan特战队出品>](http://www.jyguagua.com/wp-content/themes/begin/timthumb.php?src=http://www.jyguagua.com/wp-content/uploads/2020/03/1.jpg&w=280&h=210&zc=1)
![[整理]鲲鹏性能优化十板斧(一)——鲲鹏处理器NUMA简介与性能调优五步法<TaiShan特战队出品>](http://www.jyguagua.com/wp-content/themes/begin/timthumb.php?src=http://www.jyguagua.com/wp-content/uploads/2020/03/1-1.jpg&w=280&h=210&zc=1)